Toward Open World Robotics
Over the last 10 years we have seen a hype bubble in robotics to a large extent fueled by the explosive success of “big data” and deep learning in domains like computer vision and natural language processing. That bubble is gradually deflating as the field observes that learning has not revolutionized robotics as optimistically as previously hoped. We’re uncovering two harsh lessons: 1) “big-data” learning techniques are not sufficient for robots to adapt to new experience at deployment time, and 2) success in the lab is still a tremendous distance from success in the market. As such, robotics remains a frustrating problem, still waiting for breakthroughs.
A phrase that’s becoming more popular in the AI community is “open-world AI,” which calls for revising some of the basic tenets of AI to better align with the real-world. Open-world AI acknowledges that:
- Deployment-time domain gaps are significant roadblocks to the success of AI in many areas.
- Generalizability of methods across large domain gaps is a subject worthy of explicit study.
- Methods that explicitly target domain gaps will deploy more successfully than those that do not.
This is indeed a minor revolution compared to the traditional way that AI and machine learning (ML) has been done. Whereas standard AI/ML poses the problem of generalization to novel instances, open-world AI poses the problem of generalization to novel domains; in other words, the system should adapt to vastly out-of-distribution data or new classes seen during deployment time. I’ll first note that this concept has been referred to by many names, such as domain shift, a domain gap, distribution shift, and concept drift, but I prefer the phrase “deployment gap” here because it emphasizes that the AI/ML engineer is no longer in control of the system at deployment time.
I believe that robotics should follow suit and take on the banner of open-world robotics to define a similar (minor) revolution. Many robotics researchers have started adopting elements of this perspective in their own work and should be commended for doing so. However, this adoption has been largely organic, and it is an opportune time to articulate more explicitly what we value in open-world robotics. Just as in open-world AI, open-world robotics encompasses a philosophical stance, collection of problems, and culture of best practices that will help us become more confident in real-world deployments of our technology.

In this article I advocate for three major tenets of open-world robotics:
- A robot’s behavior should cope with large deployment gaps. Behaviors should be flexible to handle unexpected situations, adaptable to produce improved performance with more experience, and customizable to suit the needs of the developer or end-user.
- Deployment-time generalization should be adopted as the key performance objective, insofar as the robot computing research community is concerned (i.e., perception, learning, planning, and control). Papers should explicitly evaluate deployment-time adaptability by adopting the practice of development / deployment splits.
- Reliability should be treated as a field of study on its own merits. Research on methods that improve reliability at deployment time should be strongly valued and encouraged; it is as important, if not more so, than proof-of-concept work. Isolated lab demonstrations lack statistical power and should not be seriously considered as validation.
The result of the open-world robotics endeavor is to enable researchers and developers to deploy autonomous systems with confidence. Although a system will be tested in the lab, this testing will reveal the conditions under which its performance lives up to standard and when/how it degrades. In other words, deployment should not be an adventure!
Evaluating deployment-time generalization
Let’s elaborate upon how deployment-time generalization should be evaluated. A classical two-phase ML evaluation framework is to split a dataset into training and testing subsets. First, the learning method is trained on the training set, and second, its accuracy Aᵗᵉˢᵗ is evaluated on the testing set. Aᵗᵉˢᵗ evaluates the generalization of the method to unseen examples.
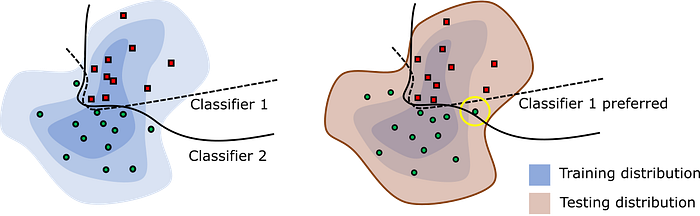
In nearly all cases we observe better performance when the testing data is representative of the training data, and worse performance when the testing data is not representative (a domain gap). We can do a better job of understanding how well the method will perform in the real-world (the deployment gap) by forcing our testing to reflect what we would expect to see at deployment time.
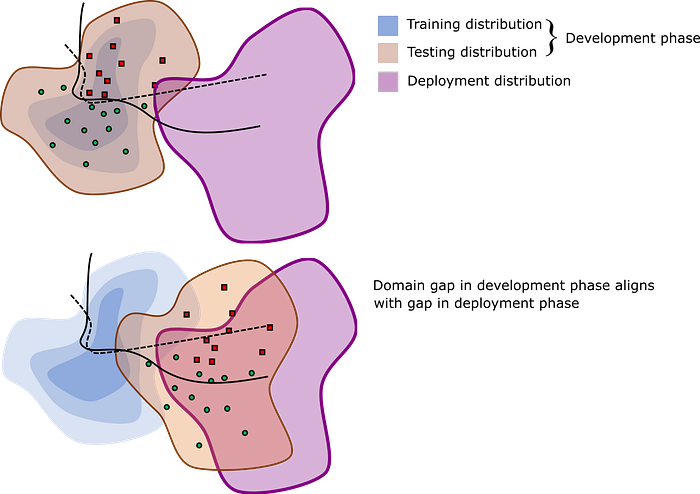
Similar practices should be adopted in robotics. First, let’s assume the simplest case of a non-adaptive system, and consider the example of a robot that grasps objects from disordered piles. We develop the system by iterating its performance on a set of objects (the development set), and by “iterating” we mean any development activity: gathering training data, designing cost functions, tweaking parameters, etc. To evaluate the robot in the lab, we test its performance on a test set. In doing so, we engineer the domain gap by prescribing the test set: we may test on different piles with the same development set (minimal domain gap), on piles of novel objects of similar shape and weight as the development set (a moderate domain gap), or on vastly different objects (a large domain gap). If a system can cope well with a large domain gap in the lab, we can be more confident that it can cross the deployment gap on the ultimate deployment set, which is never seen until the system is unleashed in the real world.

Over the last few years, the robot grasping community has done an excellent job of adopting these practices which has resulted in great success in bin-picking startups. It should be noted, however, that great care must be taken to describe the development, testing, and deployment sets precisely, and that we must not blindly seek improvements in deployment performance. If we were to improve apparent performance by making the development set closer to the testing test, this would artificially shrink the domain gap, thus telling us little about how well the system will perform upon deployment. Indeed, a truly meritorious method is one that allows a robot to generalize to large deployment gaps with the same development set. The target of one’s work should no longer be simply maximizing accuracy numbers on a fixed train/test split; one should seek graceful degradation of performance as the deployment gap grows.
Evaluating generalization with adaptive systems
To make things more complex, major improvements in deployed performance can be observed when a robot adapts to data obtained at deployment-time. In this setting a three-phase evaluation is needed.
Imagine that a learning method has access to some background knowledge available during development time, so that an offline learning phase is first performed on this dataset, and then the learner is deployed. At the start of deployment it may generalize poorly to the deployed domain, and the deployment-time performance we can expect at this stage, Aᵒᶠᶠˡᶦⁿᵉ, is essentially the same as Aᵗᵉˢᵗ. Next, we begin the online phase, which starts with the adaptation phase. We imagine that the learner is provided with a small amount of data from the deployed domain, such as a few minutes of experience or some labels provided by a human teacher. This data is known as the support set, and can be labeled, unlabeled, or mixed.
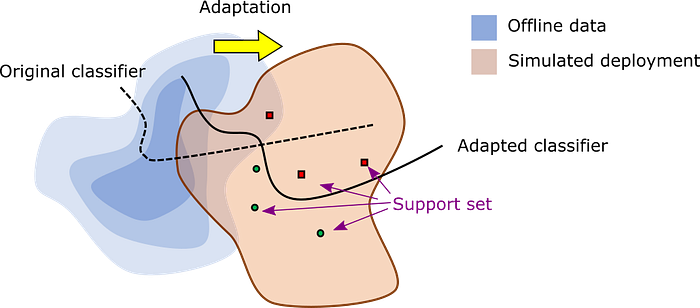
The ultimate goal is to evaluate performance on future deployment-time data after adaptation, Aᵃᵈᵃᵖᵗ. If we can evaluate Aᵃᵈᵃᵖᵗ accurately, then we can confidently deploy the learner in the real-world. Of course, deployment testing in a single environment is not likely to be informative. Instead, testing must simulate multiple deployments in which we evaluate performance on multiple problem instances (the query set). The system’s overall performance over a deployment acts like a single datapoint for estimating Aᵃᵈᵃᵖᵗ. At the start of each simulated deployment, the learner’s information state (e.g., learned parameters and memorized experience) is reverted to its original condition immediately after the offline phase.
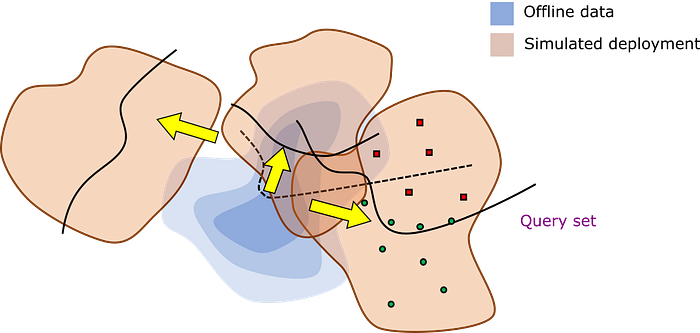
We should be evaluating adaptive robots in a similar process. (Note that the meta-learning and few-shot learning literature has adopted the term “task” to mean what I refer to as a “deployment”, but “task” is far too overloaded in the robotics literature to be meaningfully adopted.) But compared to standard evaluation, there are several new decisions that must be made:
- How much data should be provided to the system during adaptation? Do we emphasize performance in the short-term or the long-term?
- How do we engineer domain gaps in our simulated deployments such that the gap is small enough to make progress, but representative of true deployments?
- How many simulated deployments should be evaluated to reach a confident signal?
- How do we develop simulated deployments such that they are practical and somewhat repeatable across labs?
These details must be elaborated upon in any evaluation, but nevertheless these practices are becoming commonplace in fields like meta-learning and few-shot learning. Based on experience in those fields, I make the following recommendations for developing and evaluating open-world robots:
- Do not develop the robot on the testing set. Instead, split the development set into training and validation sets and iteratively improve the robot’s behavior on the validation set.
- Specify how development and testing sets are generated, including the environment settings, characteristics and layout of objects, and amount of data.
- Clarify how the gap between development and testing sets was chosen. With a verbal argument, justify how this gap is expected to be representative of real-world deployments.
- The information state of adaptive robots must be reset to a consistent state prior to a simulated deployment. Information should not leak from deployment to deployment.
- Humans may be part of the environment as well. Development/testing/deployment splits can be simulated with natural variation via human subjects studies, or controlled using “simulated humans” (associates) who behave according to prescribed interaction rules.
- Communities of robotics researchers investigating a certain topic should self-organize around a set of best practices, e.g., environments and objects, procedures to generate scenarios, etc. Although these best practices should evolve over time as technology changes, it is a good idea to keep metrics consistent for several years at a time so that researchers on that topic can benchmark progress.
Methods for open-world robotics
I do not wish to prescribe specific techniques that could be used to achieve the goals of open-world robotics, but I will comment on some relevant research being done in AI/ML today. It should be emphasized that learning has been and continues to be a positive force for the field, allowing robots to adapt to far more complex environments than previously possible with traditional methods (i.e., those that rely purely on analytical models). However, we should pay more attention to AI/ML methods tailored to the small-data regime, such as online learning, few-shot learning, unsupervised domain adaptation, semi-supervised learning, transfer learning, continual learning, and interactive learning.
Moreover, learning isn’t the end of the road, and it would be valuable to develop and evaluate other components with open-world goals in mind, such as motion planning or SLAM. Indeed, these “classical” methods are designed specifically to generalize well and will likely remain a part of open-world robots for a long time to come.
The long road ahead
Changing the culture of the robotics community for the better will be a long process. Evaluating deployment-time generalization is more time-consuming than the status quo and requires nuanced argumentation. This runs against several bad habits that we’ve developed: a demo culture for generating publicity; ease of generating new task variants with minor variations; an emphasis on single-task fine-tuning.
On top of this, there are serious technical challenges to making open-world robotics work. The deployment gap is genuinely large and unpredictable, benchmarking in robotics is hard, and guaranteeing safety with adaptive systems is difficult. But the objective of deploying autonomous systems with confidence is so essential to the future of robotics that we must start down this road sooner rather than later!
